

Introduction to machine learning
In today's technology-driven world, machine learning and data science have emerged as the most powerful tools transforming industries. From healthcare to finance, retail to entertainment, every sector is leveraging data to make smarter decisions
The demand for professionals skilled in machine learning and data science has skyrocketed in recent years. Companies are desperately seeking talent who can extract meaningful insights from data and build intelligent systems.
Understanding Machine Learning Basics
Before diving deep into the world of data science, it's essential to build a strong foundation in machine learning basics. Machine learning is a subset of artificial intelligence that enables computers to learn from data without being explicitly programmed for every task.
What is Machine Learning?
Machine learning algorithms build mathematical models based on sample data, known as training data, to make predictions or decisions without following strict programmed instructions. Imagine teaching a child to识别 fruits. You show them apples and oranges repeatedly until they can distinguish between them independently. Machine learning works similarly.
At the heart of machine learning lie two fundamental approaches that power everything from spam filters to customer segmentation. Understanding these concepts is crucial for anyone pursuing machine learning for data science.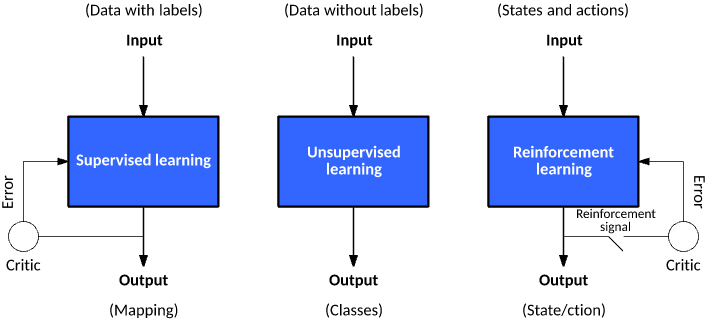
Supervised Learning: Learning with a Teacher
Supervised learning is exactly what it sounds like—the algorithm learns under supervision, similar to a student learning with a teacher's guidance. The "teacher" provides labeled examples, and the algorithm learns to map inputs to correct outputs.
How Supervised Learning Works
Imagine you're teaching a child to identify fruits. You show them an apple and say "this is an apple." You show them an orange and say "this is an orange." After enough examples, the child can identify new fruits independently. Supervised learning works the same way.
The algorithm receives:
-
Input data (features)
-
Correct output labels (answers)
-
It learns the relationship between them
-
It can then predict labels for new, unseen data
Types of Supervised Learning
Classification: Predicting a category or class
-
Email spam detection (spam or not spam)
-
Image recognition (cat, dog, bird)
-
Medical diagnosis (disease present or absent)
-
Credit risk assessment (low, medium, high risk)
Regression: Predicting a continuous value
-
House price prediction
-
Stock market forecasting
-
Temperature prediction
-
Sales revenue estimation
Real-World Applications
E-commerce Project: Predicting customer lifetime value based on purchase history (regression). Classifying customers into premium, standard, or budget segments (classification).
Healthcare Project: Predicting disease probability based on symptoms and test results (classification). Estimating recovery time based on patient data (regression).
Banking Project: Fraud detection in transactions (classification). Credit score calculation (regression).
Popular Supervised Learning Algorithms
Linear Regression: The simplest regression algorithm, finding linear relationships between variables. Used for predictions like salary based on experience.
Logistic Regression: Despite the name, it's used for binary classification. Predicts probability of an event occurring.
Decision Trees: Tree-like models that make decisions based on feature values. Easy to understand and visualize.
Random Forest: Multiple decision trees working together, providing better accuracy by reducing overfitting.
Support Vector Machines: Finds the best boundary separating different classes. Powerful for complex datasets.
Neural Networks: Multiple layers of interconnected nodes, capable of learning extremely complex patterns. Powers deep learning.
Advantages of Supervised Learning
-
Clear performance metrics (accuracy, precision, recall)
-
Interpretable results with many algorithms
-
Works well when you have labeled data
-
Established techniques with extensive documentation
Challenges
-
Requires large amounts of labeled data (expensive and time-consuming to create)
-
May not generalize well to unseen scenarios
-
Risk of overfitting (memorizing rather than learning)
-
Biased training data leads to biased models
Unsupervised Learning: Learning Without a Teacher
Unsupervised learning is the opposite—the algorithm explores data without any labeled examples. It's like giving a child a box of mixed objects and asking them to group similar items without telling them what anything is.
How Unsupervised Learning Works
The algorithm receives only input data with no correct answers. It must find patterns, structures, or relationships entirely on its own. This is both challenging and powerful—the algorithm might discover insights humans never considered.
The algorithm:
-
Receives unlabeled data
-
Finds hidden patterns or structures
-
Groups or transforms data based on similarities
-
Reveals intrinsic properties of the data
Types of Unsupervised Learning
Clustering: Grouping similar items together
-
Customer segmentation
-
Document categorization
-
Image compression
-
Anomaly detection
Association: Finding relationships between variables
-
Market basket analysis (people who buy X also buy Y)
-
Recommendation systems
-
Feature correlation discovery
Dimensionality Reduction: Reducing number of variables while preserving information
-
Data visualization
-
Noise reduction
-
Feature extraction
-
Improving algorithm efficiency
Real-World Applications
Marketing Project: Customer segmentation without predefined categories. The algorithm discovers natural customer groups based on purchasing behavior, allowing targeted marketing campaigns.
E-commerce Project: Product recommendation using association rules. "Customers who bought this laptop also bought these accessories" comes from unsupervised learning.
Social Media Project: Topic modeling on tweets or posts. Algorithms group similar content without being told what topics exist.
Manufacturing Project: Anomaly detection in sensor data. The algorithm learns normal behavior and flags unusual patterns that might indicate equipment failure.
Popular Unsupervised Learning Algorithms
K-Means Clustering: Partitions data into K distinct clusters based on similarity. Simple and widely used for customer segmentation.
Hierarchical Clustering: Creates a tree of clusters, showing relationships at different levels. Useful for understanding data structure.
DBSCAN: Density-based clustering that finds arbitrarily shaped clusters and identifies outliers. Great for spatial data.
Principal Component Analysis (PCA): Reduces dimensionality while preserving maximum variance. Perfect for visualization and noise reduction.
Apriori Algorithm: Finds association rules in transactional data. The foundation of market basket analysis.
Autoencoders: Neural networks that learn efficient data representations. Used for anomaly detection and dimensionality reduction.
Advantages of Unsupervised Learning
-
No need for labeled data (cheaper and faster)
-
Can discover unknown patterns
-
Provides insights humans might miss
-
Useful for exploratory data analysis
-
Scales well with large datasets
Challenges
-
Results are harder to evaluate (no correct answers)
-
Interpretation requires domain expertise
-
May find patterns that aren't meaningful
-
Parameter tuning can be tricky
-
Different algorithms may give different results on same data
Reinforcement Learning: Learning Through Rewards and Punishments
Reinforcement learning represents the third major paradigm of machine learning, standing alongside supervised and unsupervised learning. It's the closest approach to how humans and animals learn naturally—through interaction with the environment, receiving rewards for good actions and penalties for bad ones.
What Makes Reinforcement Learning Different?
Unlike supervised learning where you have correct answers, or unsupervised learning where you find hidden patterns, reinforcement learning involves an agent learning to make decisions by interacting with an environment.
The Core Components
Agent: The learner or decision-maker (like a program controlling a robot)
Environment: The world the agent interacts with (like a maze, game, or real-world space)
State: Current situation of the agent (position in maze, game screen)
Action: What the agent can do (move left, jump, buy stock)
Reward: Feedback from environment (positive for good actions, negative for bad)
Policy: Strategy the agent follows to decide actions
The Learning Loop
-
Agent observes current state
-
Agent chooses an action based on policy
-
Environment responds with new state and reward
-
Agent updates knowledge based on reward
-
Repeat until optimal behavior is learned
Real-World Analogy: Teaching a Dog New Tricks
Think of training a dog to fetch a ball:
-
Agent: The dog
-
Environment: Your house and yard
-
State: Dog's location, ball's location
-
Actions: Run, sniff, pick up ball, bring back
-
Reward: Treat when dog brings ball back (positive), no treat when it runs away (negative)
-
Goal: Maximize treats received
The dog learns through trial and error which actions lead to rewards. Initially, it might run randomly. Over time, it associates bringing the ball with getting treats. This is exactly how reinforcement learning works.
-
Key Differences at a Glance
| Aspect | Supervised | Unsupervised | Reinforcement |
|---|---|---|---|
| Data | Labeled examples | Unlabeled data | No data, learns from interaction |
| Feedback | Correct answers | No feedback | Reward/punishment signals |
| Goal | Predict labels | Find patterns | Maximize cumulative reward |
| Decision type | One-shot predictions | Pattern discovery | Sequential decisions |
| Temporal aspect | Independent predictions | Static patterns | Actions affect future states |
ML vs Data Science: Understanding the Difference
One of the most common confusion points for students is understanding ml vs data science. While these terms are often used interchangeably, they represent distinct but overlapping fields.
What is Data Science?
Data science is an interdisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It encompasses the entire data lifecycle:
-
Data collection and cleaning
-
Data exploration and visualization
-
Statistical analysis
-
Building predictive models
-
Communicating findings to stakeholders
Data scientists are part detective, part statistician, and part storyteller. They identify business problems, gather relevant data, analyze it, and present actionable insights.
What is Machine Learning?
Machine learning is a specific subset of data science focused on algorithms that learn from data. It's the engine that powers predictions and automates decision-making. Machine learning engineers build and deploy these algorithms into production systems.
The Key Differences
Scope: Data science is broader, covering everything from data cleaning to visualization. Machine learning focuses specifically on predictive algorithms.
Objective: Data science aims to extract insights and answer questions. Machine learning aims to make accurate predictions and automate decisions.
Output: Data science produces reports, dashboards, and recommendations. Machine learning produces models and prediction APIs.
Skills Required: Data scientists need statistics, business acumen, and communication skills. Machine learning engineers need strong programming and algorithm expertise.
How They Work Together
Think of data science as building a house. Data collection and cleaning is the foundation. Analysis and visualization are the walls and windows. Machine learning is the smart home technology that makes everything intelligent and automated. You need both for a complete, functional solution.
At Techcadd Mohali, our curriculum covers both fields comprehensively, ensuring you understand how they complement each other in real-world scenarios.
The Machine Learning for Data Science Toolkit
To succeed in machine learning for data science, you need mastery over specific tools and technologies. Techcadd Mohali ensures students gain hands-on experience with industry-standard tools.
Programming Languages
Python dominates the data science landscape. Its simplicity, extensive libraries, and strong community support make it the preferred choice. Libraries like NumPy for numerical computing, Pandas for data manipulation, and Matplotlib for visualization form the foundation.
R is popular in statistical analysis and academic research. While we focus primarily on Python at Techcadd Mohali, we introduce R for specific statistical applications.
Essential Machine Learning Libraries
Scikit-learn is the most popular machine learning library, offering simple and efficient tools for data mining and analysis. It implements various algorithms for classification, regression, clustering, and dimensionality reduction.
TensorFlow and PyTorch power deep learning applications. These frameworks build neural networks for complex tasks like image recognition and natural language processing.
Data Visualization Tools
Tableau and Power BI help create interactive dashboards. Matplotlib and Seaborn in Python enable detailed statistical visualizations.
Big Data Technologies
For handling massive datasets, tools like Hadoop and Spark become essential. Our advanced curriculum at Techcadd Mohali covers these technologies for students aiming for enterprise-level roles.
Career Opportunities in Machine Learning and Data Science
The job market for machine learning and data science professionals is exceptionally strong. Let's explore the most sought-after roles.
Data Scientist
Data scientists analyze complex data to help companies make better decisions. They design experiments, build predictive models, and communicate findings to leadership. Average salary in India ranges from ₹8-25 LPA depending on experience.
Machine Learning Engineer
ML engineers focus on building and deploying machine learning models at scale. They work closely with software engineers to integrate AI capabilities into products. Salaries typically range from ₹10-30 LPA.
Data Analyst
Data analysts examine datasets to identify trends and insights. They create visualizations and reports that guide business decisions. Entry-level positions start at ₹4-8 LPA.
AI Research Scientist
These professionals push the boundaries of what's possible with artificial intelligence. They develop new algorithms and publish research. This role typically requires advanced degrees and offers salaries exceeding ₹30 LPA.
Business Intelligence Developer
BI developers design and implement strategies to help business users find information quickly. They work with data warehouses and reporting tools. Salaries range from ₹6-15 LPA.
The Skills Employers Want
-
Strong programming skills (Python, SQL)
-
Statistical analysis and mathematics
-
Machine learning algorithms
-
Data visualization
-
Communication and storytelling
-
Business acumen
-
Cloud computing (AWS, Azure, GCP)


Comments
No comments yet. Be the first to comment.
Leave a Comment